Master Asynchronous JavaScript Like a Pro (Easy Guide!)

Possessing a high ambition of being a full-stack developer after working as a frontend engineer for some time, currently, I am expertizing in backend engineering with AWS and serverless architecture. Taking a problem, solving it, and then making it work using coding always gives me great pleasure. Moreover, as I got to taste the flavor of both the frontend and backend parts, I can easily visualize and make a bridge between them while working on any project now.
JavaScript is a powerful tool for web development, but its synchronous nature can sometimes slow things down. Enter Asynchronous JavaScript, your key to unlocking faster, smoother code!
The word asynchronous means not occurring at the same time. But in JavaScript, the code gets executed line by line as it has a single thread. So, JavaScript is synchronous by nature.
So, how do we make JavaScript act asynchronously?
To make JavaScript work asynchronously, we first need to understand how the JavaScript code executes.
To run a javascript script we need a JavaScript Engine. The purpose of the javascript engine is to translate the code developers write into machine code. The computer reads this machine code and performs the specified tasks.
So, when the JavaScript engine starts executing the code it creates Execution Context. Each execution context has two phases:
The first one is the Creation phase
The second one is the Execution phase
In the creation phase, JavaScript creates a global execution context. Then it creates a 'this' object and binds it to the global object. After this, it creates a memory heap to store variables and function references. Next, it initializes the variable within the global execution context to undefined.
In the execution phase, the javascript engine assigns values to the variables and executes the function calls. For each function call, the javascript engine creates a new function execution context. It is very similar to the global execution context. But instead of creating a global object, it creates an arguments object. This argument object is a reference to all the parameters of the function.
To understand this workflow more clearly, let’s take a look at an example:
let a = 2;
function add(c){
return c+2;
}
let b = add(a);
console.log(b);
So, this is a simple javascript code where we have 3 variables and one function.
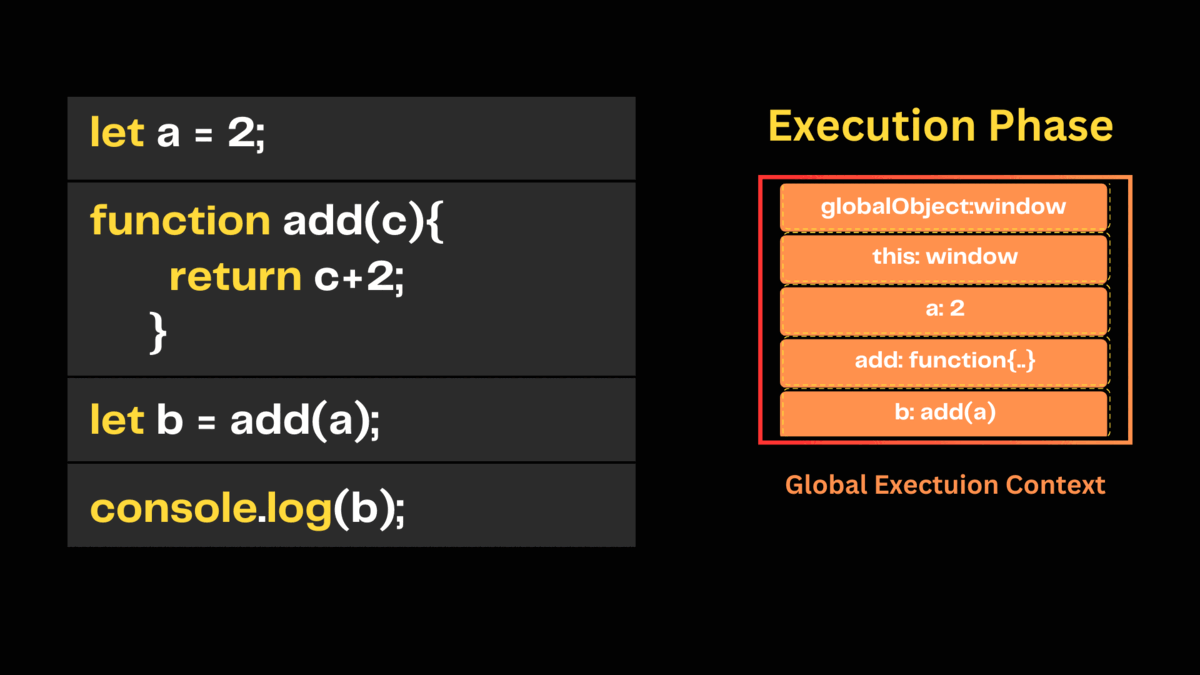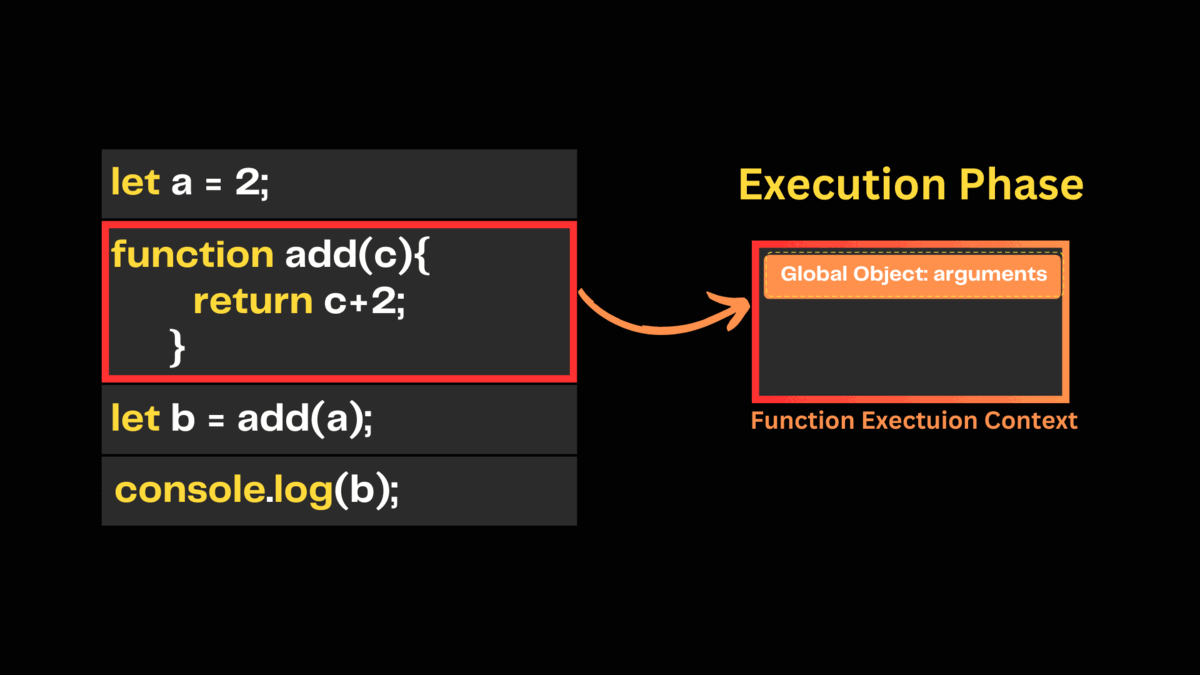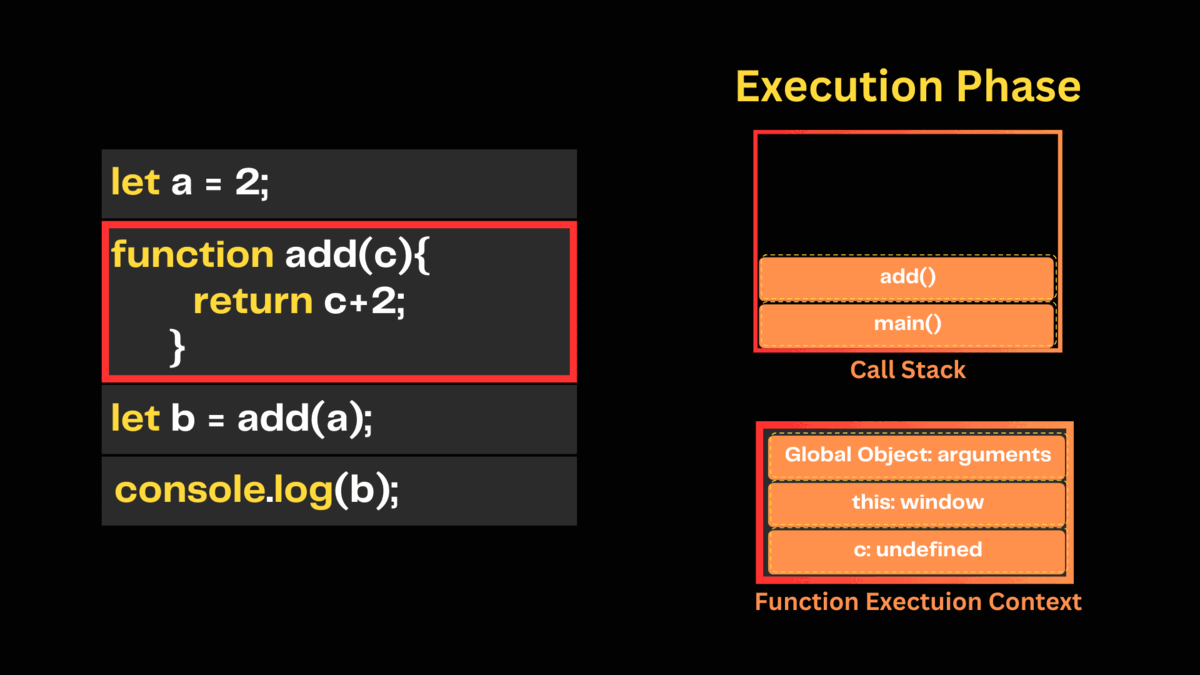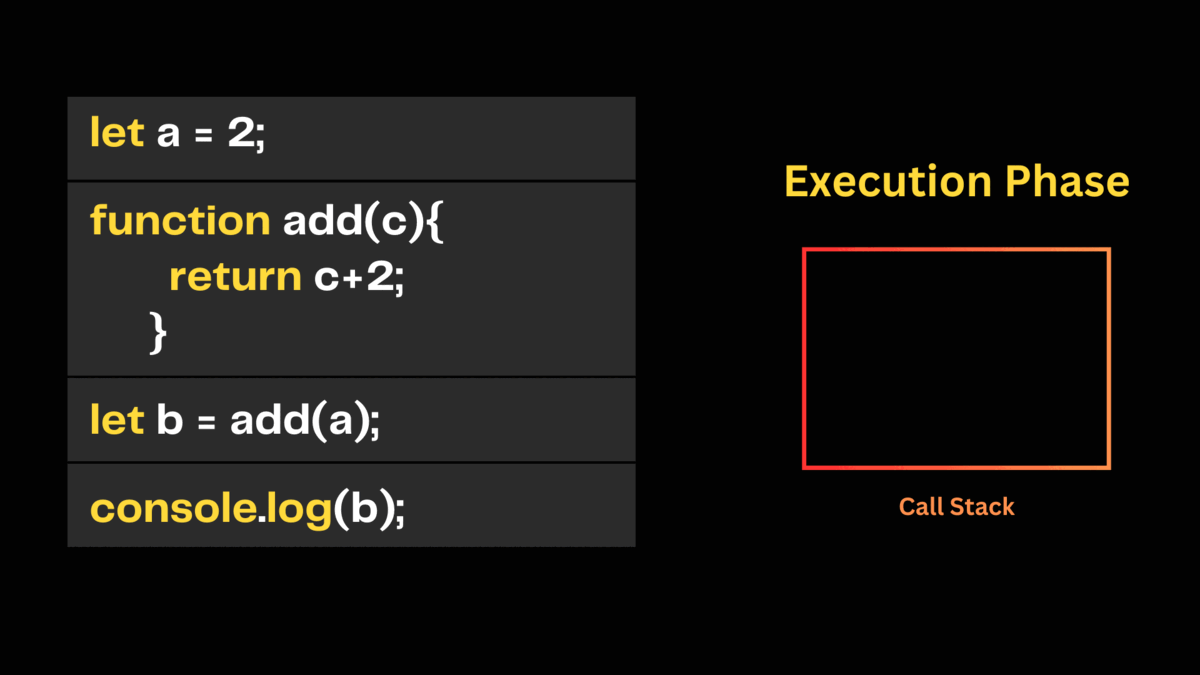
When we run this script, the JavaScript engine first goes into the creation phase and creates a global execution context. Then it creates a global object. As we use vanilla JavaScript, this global object is a window that we get from the web browser. Then it creates this object and binds it to the window object. Next, it creates a memory heap in the global execution context. There in the memory heap, it stores the variable a, b, and the declaration of the add() function. After that, it initializes the variables a and b to undefined.

After this, the engine goes into the execution phase.
In the execution phase, it first assigns values to the variables and executes function calls. For executing and keeping track of the function calls, the javascript engine maintains a call stack and there is only one call stack available in the web browser. The javascript engine places main() function from the global execution context to the call stack.
Next, for the main() function, the engine enters the creation phase. After completing the creation phase, it then moves to the execution phase.
Then javascript engine executes the call to the add() function and creates a function execution context with an argument object. This argument object keeps the references of all parameters passed into the function. Next, it sets this value to the global object and initializes parameter c to undefined. Then it pushes the add() function on top of the call stack.
After this, the engine executes the add() function on top of the call stack. During this execution phase, the engine assigns 2 to the parameter c and returns the result 4 to the global execution context. Next, it pops the add() function from the call stack.
In the final stage of the execution context, the return value from the add() function is assigned to variable b. Then the value of b is printed in the console. With this, the main() function popped off from the call stack completing all the execution contexts and the script stopped running.
So, as you can see with javascript we are doing one step at a time.
Now let’s look at another example:
console.log(1);
console.log(Math.sqrt(1024))
console.log(2);
With this code, we want to print 1, the square root of 1024, and 2 in the console. So, this is another simple example of the synchronous javascript execution. However, there is a catch. Here, we are calculating the square root of a number. Now the bigger the number the more time it will take to execute. So, other operations will be on hold till then. This situation is called Blocking and it is one of the major drawbacks of synchronous javascript.
To solve this situation we are going to implement an asynchronous mechanism. As you have read in the beginning asynchronous mechanism allows us to work on multiple things at a time.
So, to implement the asynchronous mechanism in JavaScript, we need to understand some new and interesting mechanisms of our web browsers. Our web browsers contain a JavaScript Runtime Environment. This runtime environment consists of a JavaScript Engine, Web APIs, an Event Loop, and a CallBack Queue. We are already familiar with the javascript engine. Now, let’s get to know the other three.

The Web APIs consist of various kinds of modern APIs like event listeners, timing functions, and AJAX requests. We use these APIs to manipulate the HTML, and CSS of the web pages, draw and modify graphics, and get data from the network servers.
The CallBack Queue stores the callback functions sent from the Web APIs. The queue stores these functions in first in first out order.
The Event Loop continuously monitors the state of the call stack and callback queue. When the call stack gets empty, it takes a callback function from the callback queue and puts it onto the call stack.
So, if you notice javascript is still executing synchronously. But because of using the JavaScript Engine, Web APIs, an Event Loop, and a CallBack Queue, it makes us think that javascript is executing asynchronously.
Now let’s take a look at an example to understand this whole flow. In this example, I have modified our previous code.
console.log(1);
setTimeout(() => console.log(Math.sqrt(1024), 3000))
console.log(2);
This time, in the code I have introduced a new method named setTimeout. This setTimeout() is a timing function provided by the Web APIs. This method sets a timer that executes a function or specified piece of code once the timer expires.
So, our code first prints 1 to the console.
Then it moves to the setTimeout() method. Here we have specified the square root code and a delay of 3000ms. That means this block of code will get executed after 3s.
Next, this method is moved from the call stack to the Callback Queue via Web APIs, and in the Callback Queue, the method processing keeps on running.
Then, the execution pointer moves to the third line and prints 2 to the console.
Now, as our call stack is empty, the event loop looks into the Callback Queue and takes the setTimeout method to the call stack. By this time, if 3 seconds is up it prints the square root of the given number in the console.

So, this is how asynchronous javascript works while not creating any blocking.
Wrapping Up
That's it. Thanks for stopping by. I hope by now you have a good understanding of what asynchronous javascript is and how it works.
My DMs are always open if you want to discuss further on any tech topic or if you've got any questions, suggestions, or feedback in general.
Happy learning! 💻 😄
Follow me and support me on:
🔗 LinkedIn: https://www.linkedin.com/in/suriya-ta...
🐦 Twitter: https://twitter.com/SuriyaDisha
📝 Tech Blog: https://blog.suriyadisha.com



